Understanding the Concept of Duplicate Keys in Maps
Related Articles: Understanding the Concept of Duplicate Keys in Maps
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to Understanding the Concept of Duplicate Keys in Maps. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Understanding the Concept of Duplicate Keys in Maps
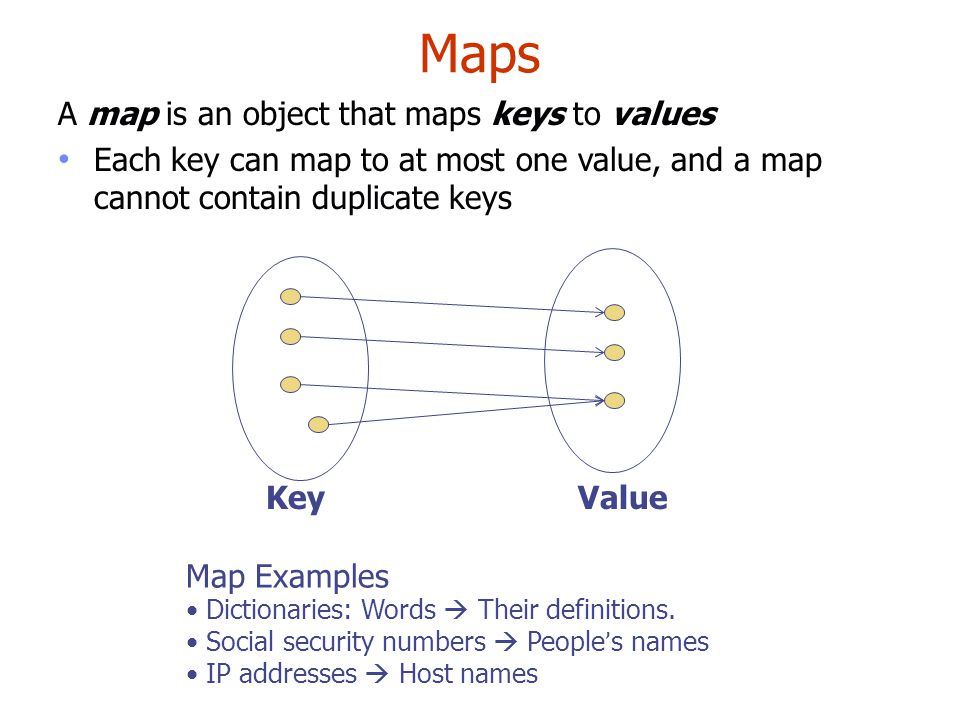
In the realm of data structures, maps, also known as dictionaries or associative arrays, play a pivotal role in storing and retrieving data efficiently. They offer a powerful mechanism to associate keys with corresponding values, enabling quick access to information based on unique identifiers. However, the fundamental principle of maps dictates that each key should be unique. This ensures that a single value is associated with a given key, preventing ambiguity and maintaining data integrity.
The concept of "duplicate keys" in maps might seem counterintuitive at first glance. After all, the very essence of a map lies in its ability to establish a one-to-one relationship between keys and values. Yet, the notion of duplicate keys arises from the specific implementation and usage context of certain map-like data structures.
The Significance of Duplicate Keys
While the conventional definition of maps emphasizes unique keys, certain scenarios demand the ability to associate multiple values with a single key. This need for "multi-valued" associations arises in various data modeling and programming situations. Consider, for instance, a scenario where you need to store a list of phone numbers associated with a particular individual. In this case, a simple map with unique keys would be inadequate. Instead, you would require a data structure that allows you to associate multiple phone numbers with the same individual’s name.
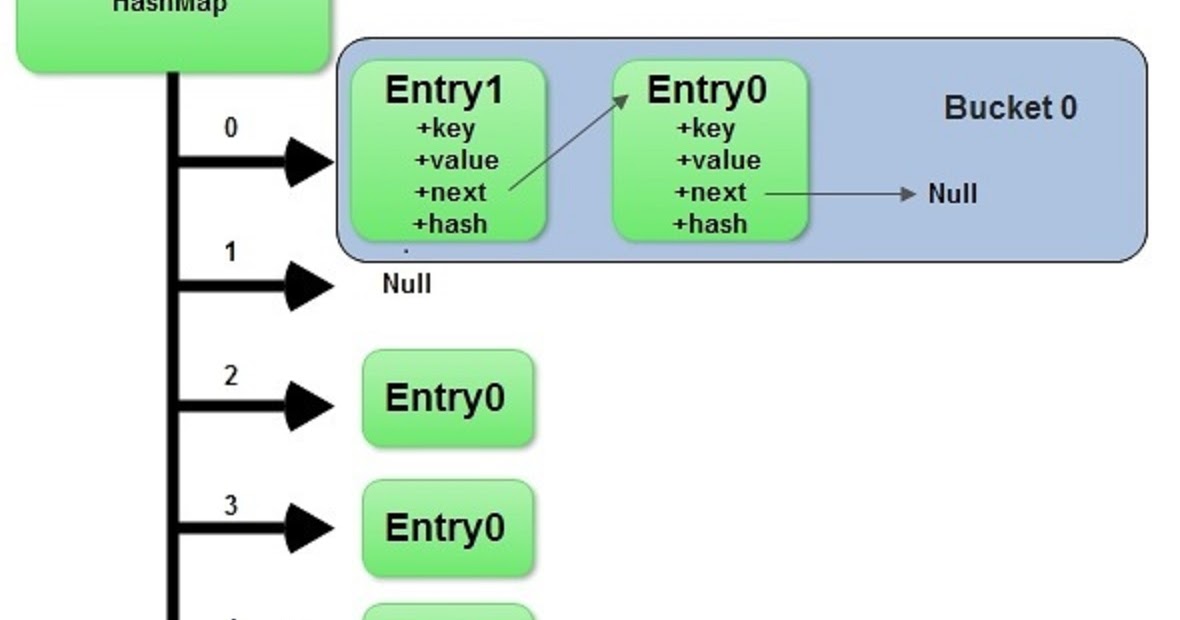
Understanding the Implementation of Duplicate Keys
The ability to handle duplicate keys in maps is often achieved through specialized data structures or adaptations of traditional maps. One common approach involves utilizing a list or a set as the value associated with a key. This allows for the storage of multiple values under a single key.
For example, in a Python dictionary, which serves as a map-like data structure, one can store a list of values under a single key:
phone_numbers =
"John Doe": ["123-456-7890", "987-654-3210"],
"Jane Doe": ["555-123-4567"]
print(phone_numbers["John Doe"]) # Output: ['123-456-7890', '987-654-3210']In this example, the key "John Doe" is associated with a list containing two phone numbers. This demonstrates how a map can effectively handle duplicate keys by associating them with a collection of values.
Exploring the Benefits of Duplicate Keys
The ability to handle duplicate keys in maps offers several advantages:
- Flexibility in Data Modeling: Duplicate keys enable the representation of complex relationships where multiple values are associated with a single entity. This flexibility is crucial in scenarios involving user profiles, product catalogs, or any data where multiple attributes can be linked to a single identifier.
- Efficient Storage of Related Data: Grouping related data under a single key simplifies data retrieval and manipulation. Instead of storing separate entries for each value, duplicate keys allow for a more compact and efficient representation.
- Enhanced Data Organization: Duplicate keys facilitate the organization of data based on meaningful categories. For example, in a product catalog, grouping products by their brand using duplicate keys allows for easy navigation and filtering.
Addressing Potential Drawbacks
While duplicate keys offer significant advantages, it’s essential to acknowledge potential drawbacks:
- Increased Complexity: Managing duplicate keys introduces complexity to the data structure. Implementing operations like insertion, deletion, and search might require additional logic to handle multiple values associated with a key.
- Data Integrity Concerns: Without careful implementation, duplicate keys could lead to data inconsistencies and ambiguity. Ensuring proper data validation and synchronization becomes crucial when working with duplicate keys.
FAQs about Duplicate Keys in Maps
Q: What are some common data structures that allow for duplicate keys?
A: Common data structures that allow for duplicate keys include:
- Multimaps: Multimaps are a specific type of map that explicitly supports multiple values associated with a single key.
- Multisets: Multisets are collections that allow for duplicate elements, which can be used to represent multiple values associated with a key.
- Dictionaries with Lists as Values: As demonstrated earlier, dictionaries can be used to store lists of values under a single key.
Q: What are some real-world examples of using duplicate keys?
A: Real-world examples of using duplicate keys include:
- Storing user preferences: A user might have multiple preferences associated with their account, such as favorite products, recommended items, or saved searches.
- Managing product inventory: A product catalog might have multiple variations of a single product, such as different colors, sizes, or materials.
- Tracking historical data: A system might store multiple data points associated with a specific timestamp, such as stock prices, sensor readings, or user activity logs.
Q: What are some best practices for working with duplicate keys?
A: Best practices for working with duplicate keys include:
- Clearly define the purpose of using duplicate keys: Ensure that the use of duplicate keys is justified and aligns with the specific data modeling requirements.
- Choose an appropriate data structure: Select a data structure that effectively supports the handling of duplicate keys, such as multimaps or dictionaries with lists as values.
- Implement data validation and synchronization mechanisms: Ensure that data integrity is maintained when working with duplicate keys, especially when performing updates or deletions.
- Document the use of duplicate keys: Clearly document the use of duplicate keys and their implications for data access and manipulation.
Tips for Working with Duplicate Keys
- Consider using a specialized data structure: Instead of adapting existing map implementations, utilize data structures specifically designed to handle duplicate keys.
- Implement efficient search and retrieval mechanisms: Optimize data access operations for scenarios involving multiple values associated with a single key.
- Utilize appropriate data validation techniques: Implement checks to ensure that data associated with duplicate keys is consistent and accurate.
- Test thoroughly: Thoroughly test data structures and operations involving duplicate keys to ensure proper functionality and prevent potential errors.
Conclusion
The concept of duplicate keys in maps, while seemingly at odds with the traditional definition of maps, presents a valuable tool for data modeling and programming. By embracing the flexibility of associating multiple values with a single key, developers can create data structures that efficiently represent complex relationships and enhance data organization. While the use of duplicate keys introduces additional complexity, it empowers programmers to model and manage data in a more nuanced and expressive manner. By carefully considering the benefits and potential drawbacks, and adopting best practices, developers can leverage the power of duplicate keys to build robust and efficient data structures that meet the demands of diverse applications.




Closure
Thus, we hope this article has provided valuable insights into Understanding the Concept of Duplicate Keys in Maps. We appreciate your attention to our article. See you in our next article!