Unlocking the Power of Dimensionality Reduction: A Guide to Installing and Utilizing UMAP
Related Articles: Unlocking the Power of Dimensionality Reduction: A Guide to Installing and Utilizing UMAP
Introduction
In this auspicious occasion, we are delighted to delve into the intriguing topic related to Unlocking the Power of Dimensionality Reduction: A Guide to Installing and Utilizing UMAP. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Unlocking the Power of Dimensionality Reduction: A Guide to Installing and Utilizing UMAP
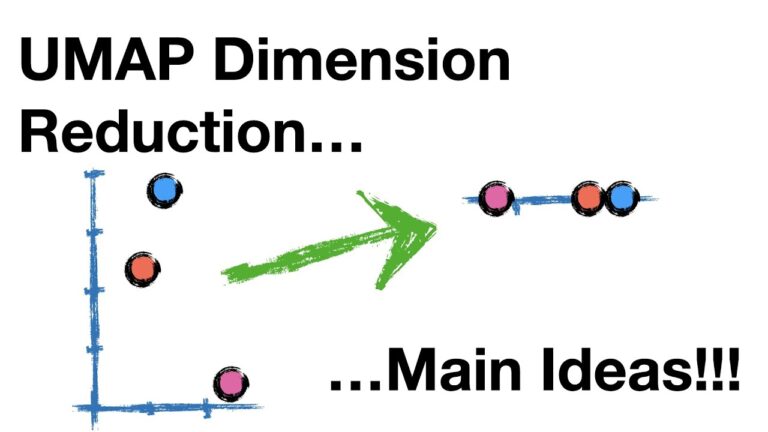
In the realm of data analysis, the challenge of navigating high-dimensional data often hinders the extraction of meaningful insights. This is where dimensionality reduction techniques come into play, and among them, Uniform Manifold Approximation and Projection (UMAP) stands out as a powerful and versatile tool.
UMAP excels in preserving the global structure of data while reducing its dimensionality, allowing for efficient visualization and analysis. This article delves into the intricacies of installing and utilizing UMAP, providing a comprehensive guide for data scientists, researchers, and anyone seeking to unlock the power of this dimensionality reduction technique.
Understanding UMAP: A Foundation for Data Exploration
At its core, UMAP aims to find a lower-dimensional representation of high-dimensional data while maintaining the essential topological structure of the original data. This means that UMAP preserves the relationships and patterns between data points, making it ideal for tasks such as:
- Visualization: UMAP enables the visualization of high-dimensional data in two or three dimensions, allowing for the identification of clusters, outliers, and other patterns that might be obscured in the original space.
- Clustering: UMAP can be used to group similar data points together, facilitating the identification of distinct subgroups within a dataset.
- Machine Learning: By reducing the dimensionality of data, UMAP can improve the performance of machine learning algorithms, particularly in cases where high dimensionality poses a challenge.
Installing UMAP: A Step-by-Step Guide
The installation process for UMAP is straightforward, thanks to its availability as a Python package. Here’s a breakdown of the steps involved:
-
Prerequisites: Ensure that Python is installed on your system. If not, download and install the appropriate version for your operating system from the official Python website.
-
Install
pip: If you haven’t already, install the package installerpipusing the following command in your terminal:python -m ensurepip -
Install UMAP: Open your terminal and execute the following command to install the UMAP package:
pip install umap-learn
Using UMAP: A Practical Example
To illustrate the application of UMAP, let’s consider a hypothetical scenario where we have a dataset of customer purchase history containing hundreds of features. Our goal is to visualize the customer segments based on their purchasing behavior.
import pandas as pd
import umap
# Load your dataset
data = pd.read_csv('customer_purchase_history.csv')
# Select relevant features for dimensionality reduction
features = ['feature1', 'feature2', 'feature3', ..., 'feature100']
data_features = data[features]
# Initialize UMAP with desired parameters
reducer = umap.UMAP(n_components=2, random_state=42)
# Fit UMAP to the data and transform it to two dimensions
embedding = reducer.fit_transform(data_features)
# Visualize the embedding using a scatter plot
import matplotlib.pyplot as plt
plt.scatter(embedding[:, 0], embedding[:, 1])
plt.xlabel('UMAP Dimension 1')
plt.ylabel('UMAP Dimension 2')
plt.title('UMAP Visualization of Customer Segments')
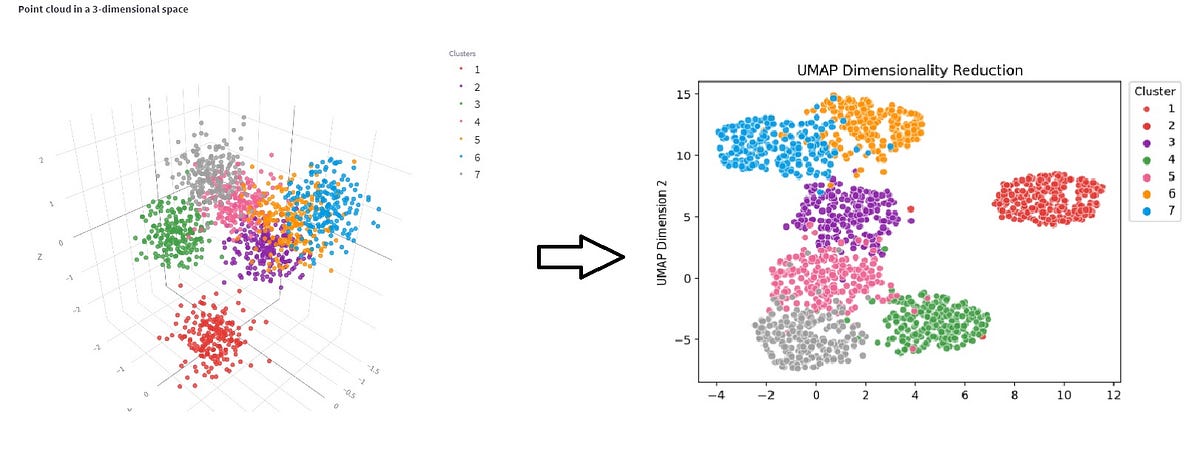
plt.show()In this example, we first load our dataset and select relevant features for dimensionality reduction. Then, we initialize a UMAP object with the desired parameters, including the number of dimensions to reduce to (2 in this case) and a random seed for reproducibility.
We fit UMAP to our data and obtain a lower-dimensional embedding. Finally, we visualize the embedding using a scatter plot, revealing distinct clusters representing different customer segments.
Beyond the Basics: Exploring UMAP’s Parameters
UMAP offers a range of customizable parameters that allow for fine-tuning its behavior to suit specific data characteristics and analysis objectives. Some key parameters include:
-
n_components: This parameter specifies the number of dimensions to reduce to. -
n_neighbors: This parameter controls the local neighborhood size used for constructing the manifold. A higher value leads to smoother, more global structures, while a lower value emphasizes local details. -
min_dist: This parameter controls the minimum distance between points in the embedding space. A higher value encourages more separation between clusters, while a lower value allows for tighter clusters. -
metric: This parameter specifies the distance metric used for calculating distances between data points. Common options include Euclidean distance, Manhattan distance, and cosine similarity.
Experimenting with these parameters is essential for finding the optimal configuration for your specific dataset and analysis goals.
FAQs: Addressing Common Concerns
Q: What are the advantages of UMAP over other dimensionality reduction techniques, such as t-SNE?
A: UMAP often outperforms t-SNE in terms of preserving global structure and handling large datasets. UMAP is also more computationally efficient and easier to interpret.
Q: How do I choose the appropriate parameters for UMAP?
A: The optimal parameters for UMAP will depend on the specific dataset and analysis goals. It’s recommended to experiment with different parameter values and evaluate the resulting embedding using visualization and downstream analysis tasks.
Q: Can UMAP be used for supervised learning tasks?
A: While UMAP is primarily a dimensionality reduction technique, it can be incorporated into supervised learning workflows by reducing the dimensionality of features before training a model.
Tips for Effective UMAP Utilization
- Data Preprocessing: Before applying UMAP, ensure that your data is properly preprocessed, including scaling and handling missing values.
- Parameter Tuning: Experiment with different parameter values to optimize the embedding for your specific dataset and analysis goals.
- Visualization: Visualize the embedding to gain insights into the data structure and identify clusters, outliers, and other patterns.
- Downstream Analysis: Use the reduced-dimensional representation for downstream tasks such as clustering, classification, and regression.
Conclusion: Embracing the Power of UMAP
UMAP stands as a powerful and versatile dimensionality reduction technique that empowers data scientists and researchers to explore high-dimensional data effectively. By preserving the essential structure of data while reducing its dimensionality, UMAP enables visualization, clustering, and machine learning tasks that would otherwise be intractable.
With its ease of installation, customizable parameters, and wide range of applications, UMAP offers a valuable tool for unlocking the insights hidden within complex datasets. By embracing the power of UMAP, data analysts can gain a deeper understanding of their data and make more informed decisions.






Closure
Thus, we hope this article has provided valuable insights into Unlocking the Power of Dimensionality Reduction: A Guide to Installing and Utilizing UMAP. We thank you for taking the time to read this article. See you in our next article!